hello,
we are running confd server on an embedded Linux device with dozen or more applications subscribing to and reading and writing into confd DB.
When operator commits a transaction into configuration DB then cpu load rises extensively for the confd process. I think It’s not as much effect of the user’s commit but the postprocessing done by all the client applications.
Or maybe I’m wrong?
Is it possible to somehow measure the load on the confd for each of the client applications to find out what is the reason for the cpu overload?
One idea that comes to my mind is to build a LD_PRELOAD approach with a wrapper library for most of the confd API what would forward the calls and gather profiling data.
But maybe there’s an easier method?
It occured to me that the LD_PRELOAD approach on the client side is still only that: profiling of the client app not profiling of the confd. I would know which of the client apps issue most of the requests to confd but I would not know the impact of the requests on the confd.
If you first want to get an overview of what’s going on between your applications and ConfD seen from the ConfD daemon side, in your ConfD configuration file, confd.conf, set the developer log level to TRACE. See the confd.conf(5) man page. I.e:
root@host2:~> confd_cli -uuser
Welcome to the ConfD CLI
user connected from 127.0.0.1 using console on host2
user@jhost2 17:01:00>config
Entering configuration mode private
[ok][2020-03-25 17:01:03]
Except buildin logs as @cohult mentioned I’d suggest to check the R/W performance of CDB itself.
As long time NSO/ConfD user I have to say you need to adjust your mindset to NSO (or try different product i.e. sysrepo/netopeer2, but not sure if it will be any better). It is not behaving like traditional databases and what in someSQL would be action of linear speed might be exponential in NSO.
First thing - the more complicated models are used, the lower R/W performance is and the more CPU is consumed. Every ‘must’ etc. Have impact on speed of R/W because ConfD/CDB must validate entries.
Second thing - despite the fact that ConfD core is written in Erlang it’s not the fastest and cpu utilization optimal when it comes to parallel R/W. There was even bug reported by us (for NSO) which caused parallel read to be magnitude slower than sequential, but this was fixed in NSO so I hope they fixed in ConfD too already.
Third thing - Erlang use it’s own ‘in-process’ threading so big part of the workload will internally be many erlang-threads while externally will be one single process on one single core. Once one core is fully utilized it becomes the bottleneck. That (erlang core) btw. means you’ll never get any more details why something is slow/CPU intensive inside NSO except the logs which are already exposed.
I know that this is not directly answering your question, but it’s more hint how to approach testing of ConfD performance.
Take pure ConfD, load the models, run R/W tests in sequence and in (massive) parallel, collect duration/CPU data, plot it, add the trendlines, take result as ‘ConfD behavior model’ (which btw. changes from version to version, usually towards better), either ‘get used to/count with it’ or change your plan.
I agree that you do have to think a bit different from just “database” here. Rather, I believe you need to adjust to thinking transactions:
Why transactions are an essential part of network automation
and the steps involved in a transaction to be able to pinpoint CPU wall-clock time performance bottlenecks.
I.e. as a user you can get quite detailed insights into what’s going on in that “Erlang blob” by dicing up ConfD and NSO transactions into their distinct steps. For example the validate phase of the transaction, where the “must” expressions that @Ivo mentioned are processed against the new configuration in the transaction.
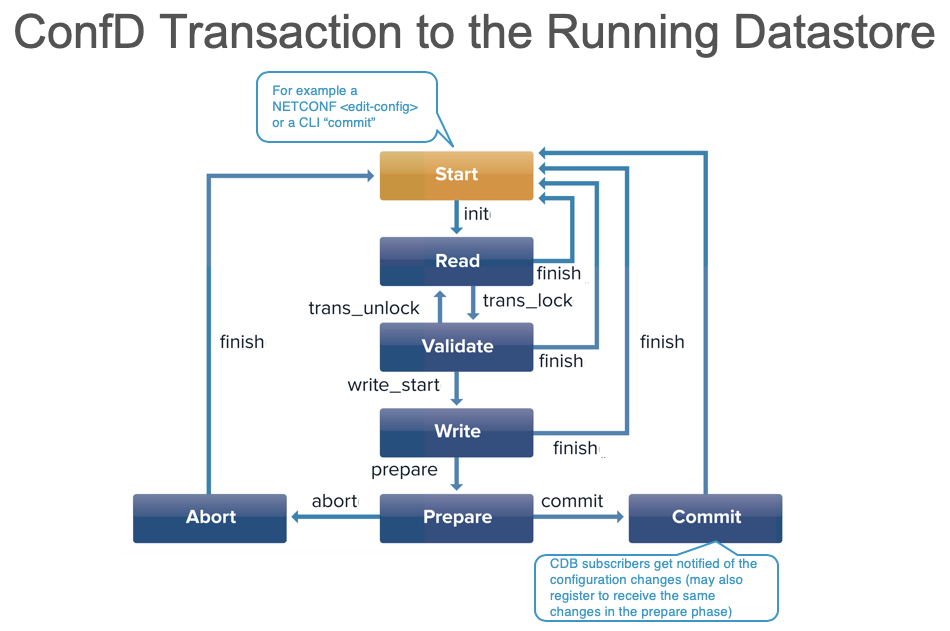
Focusing here on the steps in a ConfD transaction to the running datastore (sidenote: NSO transactions to the running datastore are similar), in short they are:
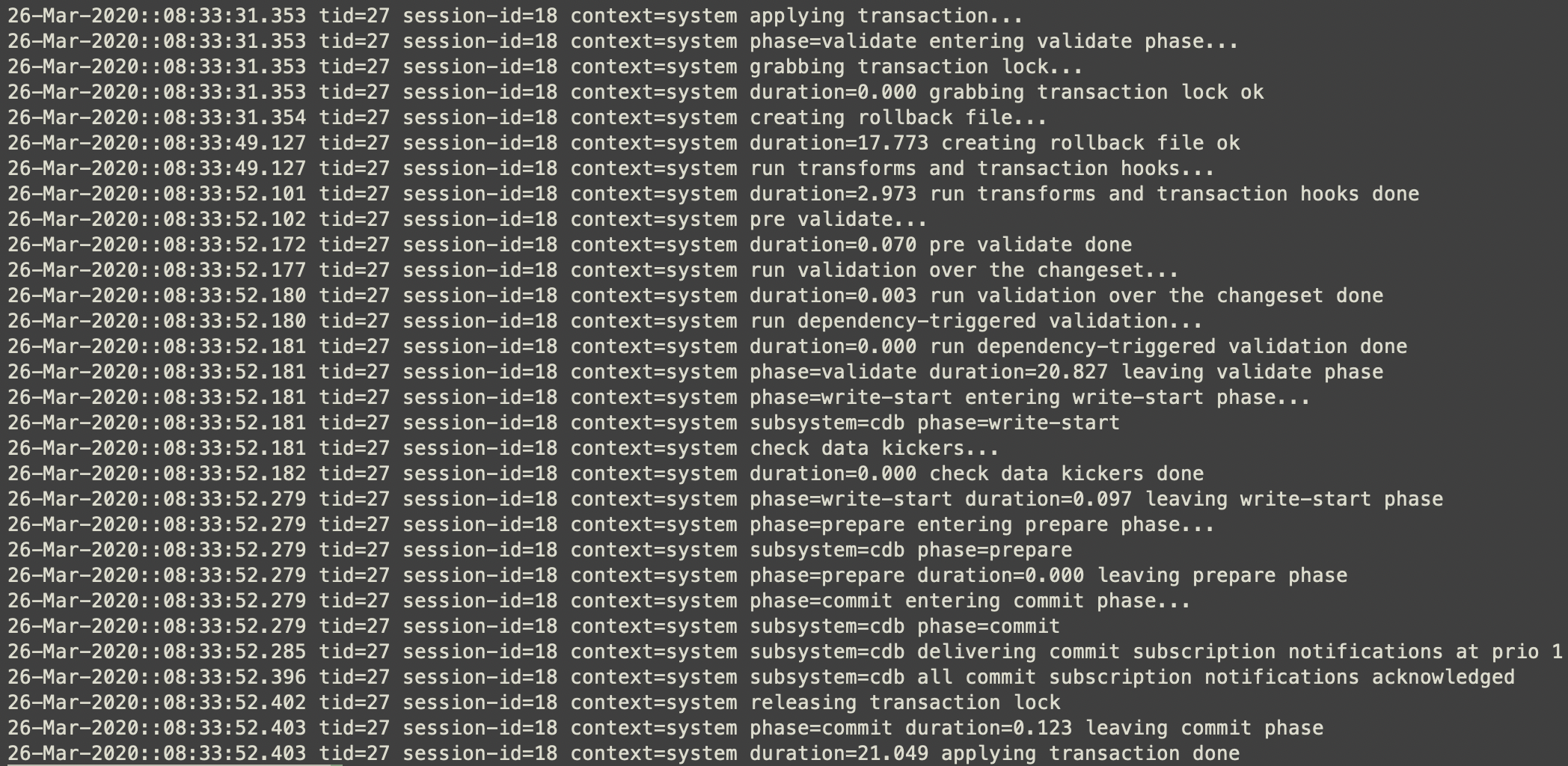
The nice thing with the progress trace, in addition to the big picture from developer log at trace level, is that the progress trace shows the timing for each of the steps taken in the transaction shown in the picture above. Including the time consumed by for example a transaction-hook callback, a validation application callback, or some “must” statements being processed.
The picture below show the transaction progress trace with “normal” level of detail when committing a large list using the examples.confd/intro/python/10-transform example together with a subscriber that just print the config changes:
Next picture describe how NSO (top box) and ConfD (bottom) perform a successful NETCONF “network wide transaction”, i.e. the ConfD candidate datastore, candidate validation, and confirmed commit of the candidate to running capabilities are all enabled. Not the fastest, but the most “robust” way of deploying a service to multiple devices / nodes.
Knowledge about why and how transactions are processed by ConfD together with the developer and progress trace will get you quite far with pinpointing performance bottle-necks in most cases.
The GitHub performance measurement demo that I pointed to above (accompanied by its slide presentation in that GitHub same repository) can also be helpful to further visualize the wall-clock time and memory peak high watermark running different loads.
Fully agree, the first thing is to get progress trace to understand the steps in transactions.
The ‘blobish’ thing I referred to is that once you’re on trace level you’d see ‘phase start…’ / ‘phase end’ message, but you have no details about why duration of phase is so long/short and why CPU goes to the skies during that phase.
Then you really need the behavioral (black box) testing to understand impact on your service/application.
I.e. ‘validate’ is nice example where changing yang model to have less ‘must’ statements and solving constrains in code might have huge impact on performance.
“must” statements with their XPaths expressions are indeed a quite common cause of performance issues. So it is worth noting that after the XPath trace was introduced a year or two ago, users can get the details of what kind of processing those XPath expressions will result in when processed by the ConfD/NSO XPath engine. See the confd.conf(5) or ncs.conf(5) man pages for details.
So at least when it comes to the validation phase, you now have some detailed insight.